Why on Earth can I start two flask dev servers on the same port?
One day at work I noticed a peculiar behaviour—on Windows, I was able to start two local flask web servers on the same address and port. My previous experience lead me to expect a EADDRINUSE error but that didn’t occur. The two servers were happily running, but only the first one was getting the requests.
First instinct, try the same thing on Linux (Ubuntu) and sure enough, there I get the Port already in use message. Interesting. To put another wrinkle into the whole thing, I try the same with netcat and what, running nc -l 127.0.0.1 8080 twice, I can run two servers on the same port on Linux as well? Not only that, with netcat, it’s the second one I started that is serving requests. What’s going on here? Let’s dig into it.
Looking at the code
First of all, we can follow the code in Flask. Flask uses Werkzeug as the WSGI library (basically an interface layer between a web application and a web server) and when we call Flasks .run(), Werkzeug spins up a local development server for us. Turns out, Werkzeug actually uses the python’s built in http.server library.
Let’s reduce the surface of the problem then, we can test this directly with http.server and not worry about Flask, see if we get the same thing. Sure enough, running python -m http.server 8080 --bind 127.0.0.1 twice gets us the same error on Linux. On Windows, no error.
Alright, let’s look at the code for http.server. On first glance, we notice something interesting, there’s a property called allow_reuse_port which is set to to true on the underlying socketserver.TCPServer class. This options triggers some code that configures the socket with SO_REUSEPORT to True using setsockopt. That seems important. Frankly, I didn’t know we can reuse ports, which is what the name SO_REUSEPORT would suggest.
But if we do set it, then why doesn’t it work on Linux, but it does on Windows? Well, sort of works, you might expect the second server to serve the requests, not the first one. I did some googling and found people asking similar questions. Found an issue on GitHub about the behaviour on Windows and a related StackOverflow thread.
Tracing on Linux
The research led me to the idea of using strace to actually see the behaviour in action. strace is a handy utility to show syscalls that a process is calling. It’s only for Linux, but let’s start there.
Running
strace -e trace=network python -m http.server 8080 --bind 127.0.0.1
lets us look at the network related syscalls that the python process is doing as it starts up the server:
socket(AF_INET, SOCK_STREAM|SOCK_CLOEXEC, IPPROTO_IP) = 3- create a socket, we get 3 in return as a file descriptorsetsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0here we set the option for file descriptor 3 calledSO_REUSEADDRtoTrue, and get 0 (success) as a resultbind(3, {sa_family=AF_INET, sin_port=htons(8080), sin_addr=inet_addr("127.0.0.1")}, 16) = 0here we bind the socket to the address and port, get 0 (success) as a resultlisten(3, 5)marks the socket as passive, used for listening- then we start
poll()ing it to be notified of incoming connections (this is actually not a network syscall but a file descriptor syscall so it can’t be seen with this filter—remember, a socket is just a file) - If we actually
curl 127.0.0.1:8080then we see anaccept()syscall to accept an incoming connection
Okay, I see the issue here. http.server sets SO_REUSEADDR to True, but not SO_REUSEPORT? How come, when we found that the source code sets allow_reuse_port to True?
Sidenote: On my machine, I also see some other unix sockets being opened (but as a client, not for listening) but I think we can ignore them for our purposes. I think it’s http.server trying to connect to a NSCD daemon via a socket for DNS resolution.
This is when I realized that I was looking at the main branch and that this line was added only in June 2024. Hence it’s not actually present in any currently released Python version! It might come in 3.14. I’ll get back to this at the end of the article.
Just to double check, let’s use strace to check netcat
> strace -e trace=network nc -l 127.0.0.1 8080
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3
setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
bind(3, {sa_family=AF_INET, sin_port=htons(8080), sin_addr=inet_addr("127.0.0.1")}, 16) = 0
listen(3, 1) = 0`
And therein lies our explanation on why it works with netcat on Linux, it does use SO_REUSEPORT. There’s actually no way to change it other than modifying code and compiling a new version. Apparently some packaged nc versions might have it disabled.
Tracing on Windows
Okay, so on Linux, http.server actually doesn’t set SO_REUSEPORT, so we can’t reuse ports. Why does this work on Windows regardless?
I first wanted to try tracing using strace but I haven’t found a simple good alternative. However I found a program called API Monitor which let’s you do a similar thing, though of course with a GUI… It’s also in alpha. On the Windows platform, you don’t use syscalls as much as call win32 APIs, for example winsock for all your socket-related needs.
In API Monitor, we can start our python http.server and trace only network related APIs.
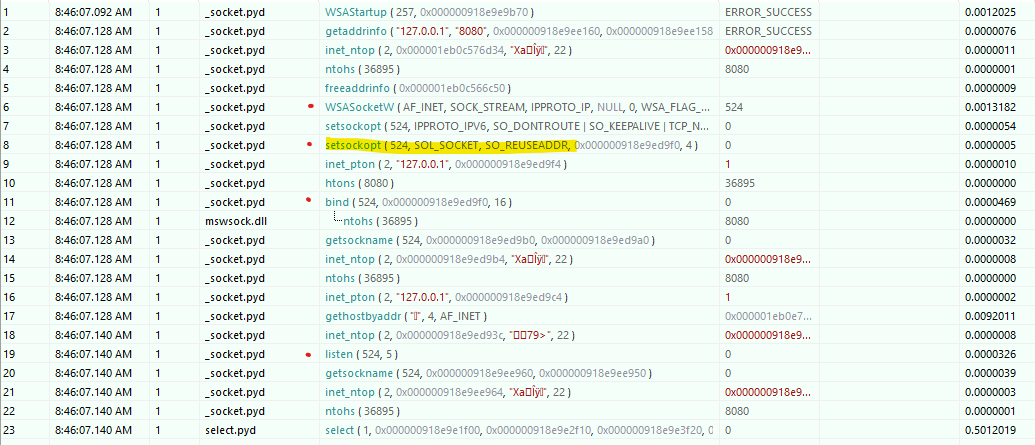
Here, we see that we again don’t set SO_REUSEPORT, just SO_REUSEADDR. This makes sense as it’s the same python code. So why can we start two of them at the same time?
Well, the answer is that handling of socket reuse in Windows is…lenient. As mentioned in this incredibly detailed StackOverflow answer:
Windows only knows the
SO_REUSEADDRoption, there is noSO_REUSEPORT. […] Prior to Windows 2003, a socket withSO_REUSEADDRcould always been bound to exactly the same source address and port as an already bound socket, even if the other socket did not have this option set when it was bound. This behavior allowed an application “to steal” the connected port of another application. Needless to say that this has major security implications!
Microsoft realized that and added another important socket option:
SO_EXCLUSIVEADDRUSE. SettingSO_EXCLUSIVEADDRUSEon a socket makes sure that if the binding succeeds, the combination of source address and port is owned exclusively by this socket and no other socket can bind to them, not even if it hasSO_REUSEADDRset.
http.server sets SO_REUSEADDR but not SO_EXCLUSIVEADDRUSE, hence reuse is allowed.
Just for fun, how can we force the behaviour? We can subclass http.server and set SO_REUSEADDR to False:
import http.server
class RequestHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
return "hello"
class CustomHTTPServer(http.server.HTTPServer):
def server_bind(self):
self.allow_reuse_address = False
super().server_bind()
with CustomHTTPServer(("127.0.0.1", 8080), RequestHandler) as s:
s.serve_forever()
And look, OSError: [WinError 10048] Only one usage of each socket address (protocol/network address/port) is normally permitted.
There are many details around combinations of SO_REUSEADDR, SO_REUSEPORT and how different OSes handle it, wildcard versus specific address binds, and this post is too long already, so I can only link the aformentioned StackOverflow answer which goes through all of this in more detail. Especially on Windows it can get confusing really fast and I’m somewhat out of my depth here.
Apparently, when multiple things are listening on the same port, the OS randomly picks where to send the request. Winsock documentation also mentions this:
Once the second socket has successfully bound, the behavior for all sockets bound to that port is indeterminate. For example, if all of the sockets on the same port provide TCP service, any incoming TCP connection requests over the port cannot be guaranteed to be handled by the correct socket — the behavior is non-deterministic.
Why do we reuse the socket in the first place?
So why is it actually useful to reuse a socket? Originally, SO_REUSEADDR=True (not SO_REUSEPORT) option was added to http.server back in 2000 and the commit message provides a hint: “Set HTTPServer class variable allow_reuse_address to 1, so restarting the server after it died doesn’t require a wait period.” The fantastic StackOverflow answer I mentioned above provides further explanation:
If
SO_REUSEADDRis not set, a socket in stateTIME_WAITis considered to still be bound to the source address and port and any attempt to bind a new socket to the same address and port will fail until the socket has really been closed. So don’t expect that you can rebind the source address of a socket immediately after closing it. In most cases this will fail. However, ifSO_REUSEADDRis set for the socket you are trying to bind, another socket bound to the same address and port in stateTIME_WAITis simply ignored, after all its already “half dead”, and your socket can bind to exactly the same address without any problem.
I’m not completely sure about this, but what it boils down to is that, for a lightweight development server, socket reuse allows us to do restarts faster.
What did we learn?
Well, Linux is strict on socket reuse. Windows, on the other hand, is very lenient on socket reuse. strace is a great tool on Linux to log syscalls and API Monitor is a great tool on Windows to show all the Windows API calls.
So is Python 3.14 going to change the default behaviour for socket reuse in http.server? I think that’s uncertain, as funnily enough, people are concerned about the change introduced in June, and there is an ongoing open issue about this.
Update: as of June 2025, the changes was rolled back in Python 3.14.