Desired state systems
In December 2021 I had the opportunity to present a talk called “Desired state: how React, Kubernetes and control theory have lots in common” at NDC Oslo 2021. This is a text version of that talk. In this post I want to share with you a certain type of abstraction that I’ve encountered over the last couple of years working across the stack. It’s a model that comes up again and again in various areas of computing, from UI engineering to infrastructure management, databases, programming language theory etc.
For lack of a better term, we could call that abstraction desired state, but that name only describes a part of it. I’ll go through some of the ways that we can look at this abstraction and show some examples of where it’s used. My hope is that by the end you’ll be able to not only spot this abstraction in the tools and APIs you encounter, but also be able to assess whether it’s worth using in your projects.
Outline
I will start with some general motivation and go through a simple example of how we can look at systems even outside of our domain with this abstraction in mind. This will give us some general principles that underlie this model. Then I’ll present several different angles from which we can look at this abstraction, with examples from well-known tools like React, Kubernetes, and Terraform. At the end I’ll mention the things you should think about when applying this abstraction yourself.
Mental models
All models are wrong, but some are useful. Working with software, we constantly deal with models, most intimately in the case of our internal, mental models of how things work and it can be useful to look at different fields, industries or areas within and try to spot connections between concepts across them and find common models. Sometimes you find seemingly unrelated things that rhyme with each other.
Your models will never be perfect, but that’s not the point. When learning new things, these can be more easily mapped to your existing mental models. Kind of like when learning languages – the more languages you know, the easier it gets (whether that’s human languages or programming languages). The syntax changes, but the underlying models often doesn’t. It allows one to think more clearly about things especially when the brain fog sets in in a long Teams meeting.
Abstraction or interface?
The desired state systems I want to describe can be found in common tools and libraries within frontend web development, backend development, databases, infrastructure, GUIs and others. It’s a model of an abstraction, but it’s closely tied to the notion of an interface, as the abstraction fundamentally changes how we as developers, or our users, or other systems, interact with a system.
What is even an abstraction? The authors of the wonderful book Concepts, Techniques, and Models of Computer Programming define it as any tool or device that solves a particular problem [1].
That’s a very general and correct definition but I especially like the take of Joel Spolsky, who simply states that abstractions are pretending. He says: “What is a string library? It’s a way to pretend that computers can manipulate strings just as easily as they can manipulate numbers. What is a file system? It’s a way to pretend that a hard drive isn’t really a bunch of spinning magnetic platters that can store bits at certain locations, but rather a hierarchical system of folders-within-folders containing individual files that in turn consist of one or more strings of bytes”.[2]
Abstractions are central to what we do. I find that the most rewarding work is not writing programs but rather designing abstractions. Programming a computer is primarily designing and using abstractions to achieve new goals. It’s exciting when you can build something which hides away some of the underlying complexity and present a simpler interface for whoever or whatever is using your system.
This was all rather abstract, so let’s get to an example from everyday life.
Elevator
Consider an ordinary elevator.
You come up to it and see the buttons with arrows pointing up and down. I don’t know about you, but growing up, my brain always interpreted the up and down arrows as “I want the elevator to go up” and “I want the elevator to go down”, instead of “I want to go up” and “I want to go down”. In other words I wanted to directly control it. To this day it sometimes takes a tiny bit of my mental capacity to remember this rule.
To a person coming to the elevator, what do the buttons represent? They’re the elevator’s interface. A device that allows the user to communicate with the system. We can think of a user as just another system, and arrive at a generalized definition of an interface as any point where two systems interact. Now, my possible confusion could stem from the fact that an arrow pointing somewhere can both mean “I want to go there” and “I want this thing to go there”. There’s probably not many people who share this confusion. Let’s ignore the question of interpreting the user interface and compare the two approaches as if they were both entirely valid.
What could we call these two approaches?
In my kid-brain approach, I wanted to tell the machine exactly what to do. In other words, how to achieve what I want it to do. I wanted to give it commands. Someone with knowledge of latin would then maybe suggest we call this an imperative approach.
In the other approach we simply tell the machine what we want to do and let it figure out how to do it. We declare what we want. So maybe we could call it a declarative approach.
Using an imperative interface, we tell the machine exactly how to do what we want - how to get to our floor. Using a declarative interface, we tell it what we want to do.
It then runs a small piece of logic that determines how to actually move the elevator. That piece of logic has to account for several things, such as - where the elevator is, which floor the caller is on, and so on. If the elevator is above us, it needs to go down, if it’s below us, it needs to go up.
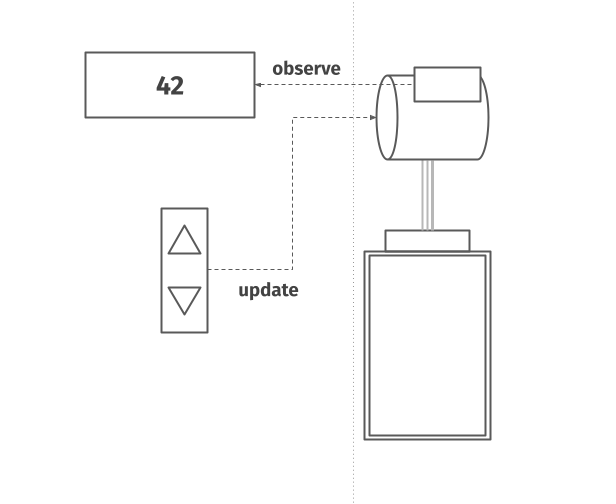
Using an imperative interface, it’s actually us who would be responsible for figuring this out. To do that, we need to be able to obtain the information about where the elevator is, which might be provided for us with a display. (though that’s not always the case, which quickly disproves the validity of my kid-brain interpretation) Only having this piece of state in hand, can we decide what command to give to the machine.
In the declarative approach, we don’t need to know anything about the state of the elevator.
Observation 1: Declarative interfaces are stateless
Note that in my example, when using a declarative interface, we are actually providing the elevator with two pieces of information – we want to get on the elevator (wherever it is) and also that we want to go up or go down once we get on it.
Let’s simplify our example for a second by separating these two concerns and focus only on the first one - we signal that we want to get on the elevator. In such a case all we need is a single button, right? And simple elevators like that of course exist.
We went from two buttons to one. What does that imply?
Observation 2: Declarative interfaces give us less control
Counter to that, the imperative approach gives you a higher degree of control - you can make the elevator go up or down, regardless of where you stand (two buttons) Again, not that it makes too much sense in the context of normal everyday elevators, but you could do it. The declarative approach gives you in a certain way less control - the elevator always goes to us (one button).
However, you probably see that’s not the full picture.
What my kid-brain didn’t really think about is that the entire point of an elevator is that it can service multiple floors. The elevator interface isn’t just the buttons on your floor, it’s buttons on all the floors, and also the buttons inside the elevator.
Once you have the full picture, you see the imperative approach would never work. How would you deal with multiple people controlling the cabin at the same time concurrently? What if you weren’t quick enough and from the time you looked on the screen to pushing the button, the elevator whizzed by and you sent it further away? What if two people on different floors kept mashing opposite inputs, making the elevator oscillate in place?
What the declarative approach takes away in control, it gives back in being able to fix these problems. For example, we can simply use a first-come-first-serve scheme to eventually handle all people on the different floors, based on the time when you pressed your button.
Observation 3: Declarative interfaces simplify concurrency
But this isn’t very efficient – we know that if people from multiple floors want to go in the same direction, we should stop on the way. Well, what if the user told us beforehand where they want to go.
Then we can optimize the operation of the elevator, and take on more people that need to go down when the cabin is going down and vice-versa. You could call this piece of information a domain specific parameter. In the end, that’s why there are two buttons, and that’s why they symbolize where we want to go and not where we want the cabin to go directly.
In some very tall buildings, you can even choose the exact floor you want to go to before boarding the cabin, which allows further optimization.
Observation 4: Declarative interfaces help with optimization
The point is that by taking away imperative control, and adding domain specific parameters, we are able to optimize the operation quite a lot. The commands to the motor can be queued, reordered, and so on. It gives us the ability to make the elevator work for multiple floors and multiple people using it concurrently. It allows us to build better and better optimizations and completely hide the mechanics of the underlying system.
Observation 5: Declarative interfaces provide encapsulation
Note that the elevator is doing the same thing. Going up or down, stopping at this or that floor. So something inside has to have direct imperative control of the elevator, otherwise it wouldn’t matter that we want to go somewhere, it wouldn’t move. A way I like to think about this is that the declarative interface wraps around the imperative interface.
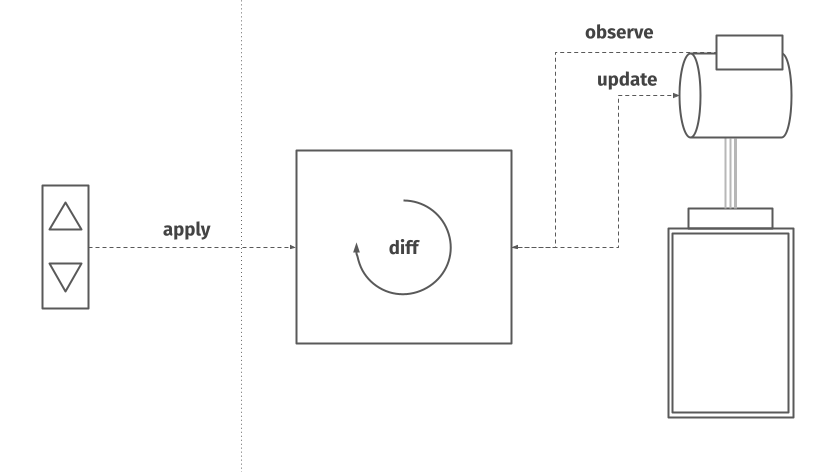
This wrapping is just another word for abstraction. It is this type of abstraction that I see everywhere around me. We could call this abstraction desired state. We give the system our desired state – we want the elevator on our floor – and let the system take care of the process of bringing the actual state of the elevator in line with our desired state. In order to do so, it must be able to query the underlying system to obtain the current state, compare or diff it to the desired state, and issue commands to it which update the actual state accordingly. In order to differentiate between the various words, let’s use the verb apply for the act of giving the desired state to our system.
Let’s generalize these principles.
Desired state system
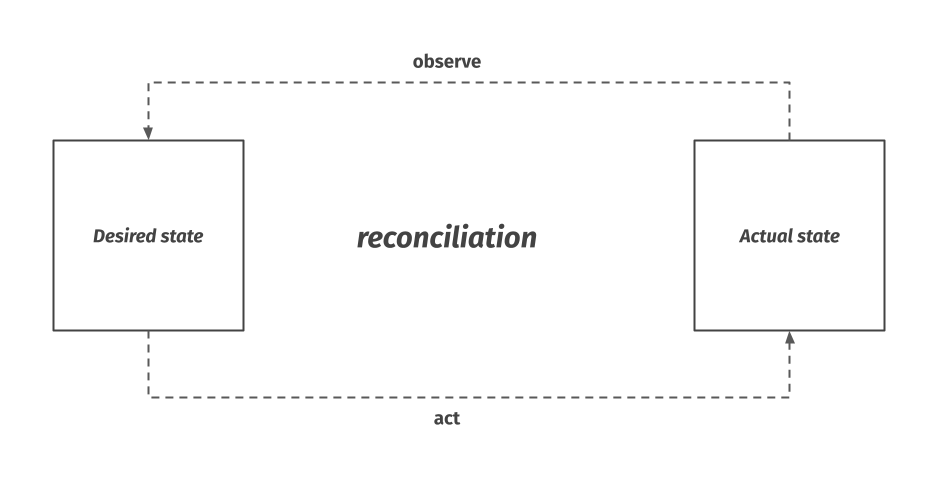
A desired state system wraps an underlying API or system which has an imperative, mutable interface and allows its user to specify a desired state for this underlying system. The wrapper is then responsible for figuring out the actual state of the underlying system, compare it to the desired state given to it by the user, and apply the necessary changes to bring the actual state in line with the desired state.
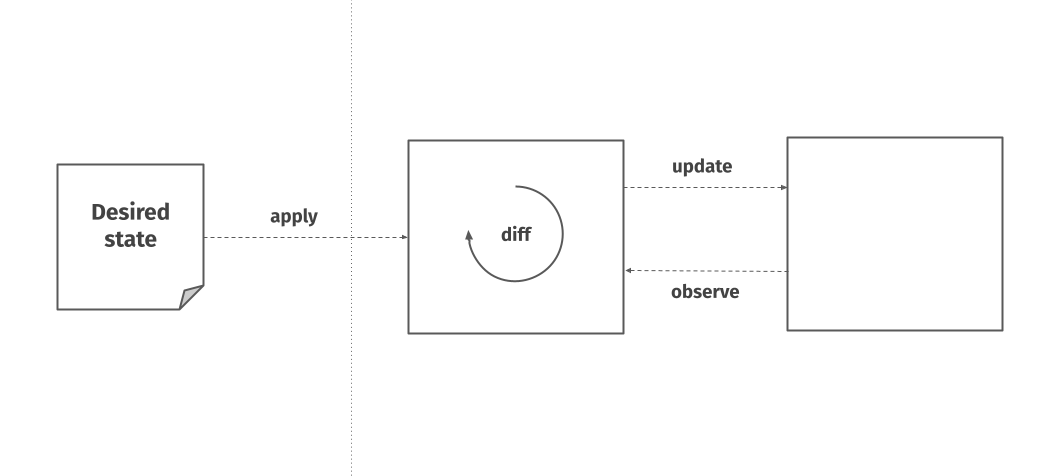
The part in the middle, where it goes through this loop of observing the underlying system, comparing its actual state to the desired state and acting on it accordingly is called reconciliation.
As I mentioned in the example, we can think of this abstraction in several different ways.
1. Declarative over imperative
For one, as a declarative interface wrapping over an imperative interface. An interface where the user simply states what they want to do is going to be simpler. It can also be beneficial by restricting the surface of the API and steering the user into the wanted patterns of usage. Many tools also utilize the fact that desired state can be version controlled, which aids in testability and auditability.
2. Stateless over stateful
We can also think of it as a stateless interface wrapping over a stateful interface. Why do we want to minimize having to keep track of state? It makes systems more understandable, and again, testable. The API becomes simpler and easier to maintain, which means it becomes more reliable. Being able to reason about effects of changes to a particular system is extremely important, particularly when dealing with concurrency.
3. Immutable vs mutable
Another way of looking at it is that we are wrapping an API with mutable semantics with an API with immutable semantics. In some cases, this abstraction allows us to treat our underlying system as an immutable object that cannot change. If something has changed, we can think of it as a new object. This again helps with reasoning about the effects of the change.
These are just three of the many possible axes that we can use to analyze a desired state system, and it’s useful to keep them in mind as we go through the examples.
Let’s first look at React, which uses a somewhat simplified version of a desired state system.
React
React is a popular JavaScript library for building user interfaces. It lets you define how you want your application to look and behave, all within JavaScript.
You define your app as a tree of composable components that serve as the input to React. The tree defines the structure of the application, while the look is controlled by the various properties applied to the components of the tree and the behaviour is controlled by various callback functions that trigger on user inputs or some phase of a component lifecycle. The leaves of the tree represent the actual HTML elements to be displayed.
The tree is essentially a giant nested call of React’s createElement function. The first argument to this function is the type of the node we want to use, this can either be a component defined by us or a leaf node with a specific HTML element. The second argument are the properties we want to send to this component and the third argument specifies the children for the component node in the tree. This interface makes components very composable, as you are able to quite dynamically pass data, callbacks and even other components from a parent component to a child component in this tree. This allows React to express many useful design patterns in React.
In order to save typing and bring the syntax more in line with actual HTML, many people use a syntactic sugar called JSX, which makes the function calls a bit more compact.
React wraps around the browser document object model, or DOM, which is a deeply imperative API present in all web browsers. This API lets us programmatically alter the contents of the page. It represents the HTML page as a tree of nodes with attributes, properties, event handlers and offers methods for querying, creating new elements, appending new children in the tree and so on. React’s component tree has a similar structure.
React as a desired state system
Let’s look at React through the lens of desired state. When the page loads, some initial desired state in the form of a component tree is given to React. Internally, React keeps a representation of this tree in memory and whenever the desired state changes – based on the user input or other triggers – it compares the old state to the new state. This internal representation used to be called the virtual DOM, though that name isn’t used much anymore.
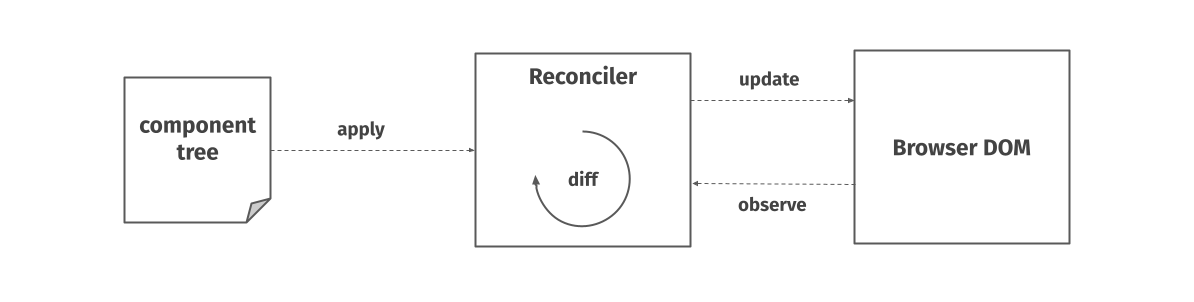
The comparison of states generates a sequence of operations that need to be performed on the actual DOM. Generic algorithms for generating the minimum number of operations needed to transform one tree into another have complexity in the order of O(n^3) where n is the number of elements in the tree. However, React has to do this really fast, and so it uses a series of heuristics to compute the least number of operations necessary.
This brings the time complexity down to O(n). These heuristics rely heavily on two assumptions – First, two elements of different types will produce different trees and second, the developer can hint at which child elements might not change across different renders with a specific property called a key. This is needed for lists and other places where order is important. React also relies the fact that the properties passed down to the children are immutable – it assumes that when an object’s contents change, so does the reference to this object. React can then do simple reference comparisons without doing deep diffing and re-render components when their properties change. This keeps the UI responsive.
The reason I stress this is because the structure of your state and how difficult it is figure out how to change it when two versions of it are compared, can be one of the crucial parts of building a desired state system.
The reason React computes the minimal operations necessary, is because operations on the DOM are really slow. However, the entire diffing mechanism is an implementation detail and React could choose to just reconstruct your entire tree from scratch every time, if it was performant.
Now I want to get to the point that React is a simplified desired state system according to the model we are working with. Let me digress for a second to basics of control theory.
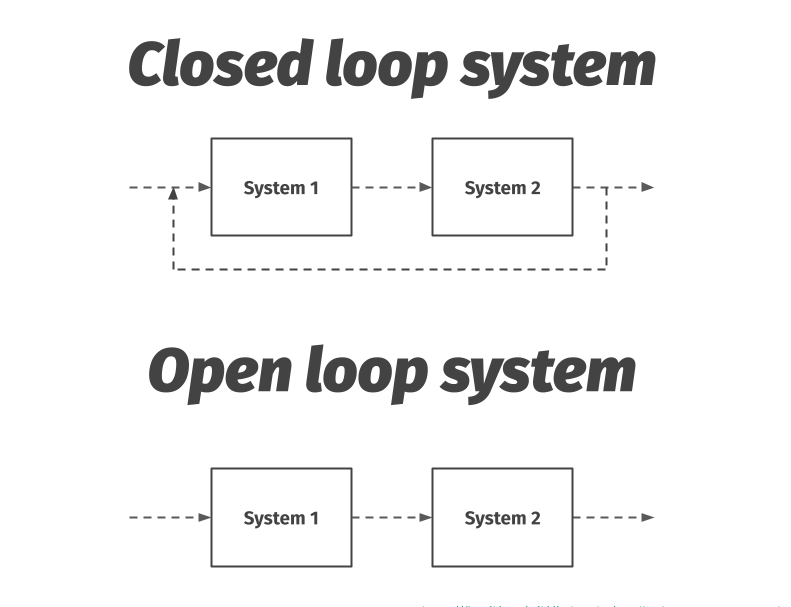
Control theory: closed vs open loop
We say that a closed loop system is one that is interconnected in a cycle. If System 1 gives signals to System 2, the outputs of System 2 are in some way a part of the input to System 1. This is called feedback. A key feature of feedback is that it provides robustness to uncertainty. Closed-loop systems automatically achieve and maintain the desired output condition by comparing it with the actual condition.
While feedback has many advantages, it also brings a set of drawbacks. If not designed properly, the system can exhibit instability. This could be in the form of positive feedback, like when a microphone’s amplifier is turned up too high in a room. Furthermore, feedback inherently couples different parts of the system. [3]
On the other hand, in an open loop system, this interconnection is severed.
React is an open loop system
While React is a desired state system within our model, it’s actually an open loop system. React does not keep rechecking the current state of the Browser DOM to see if it’s in the correct shape.
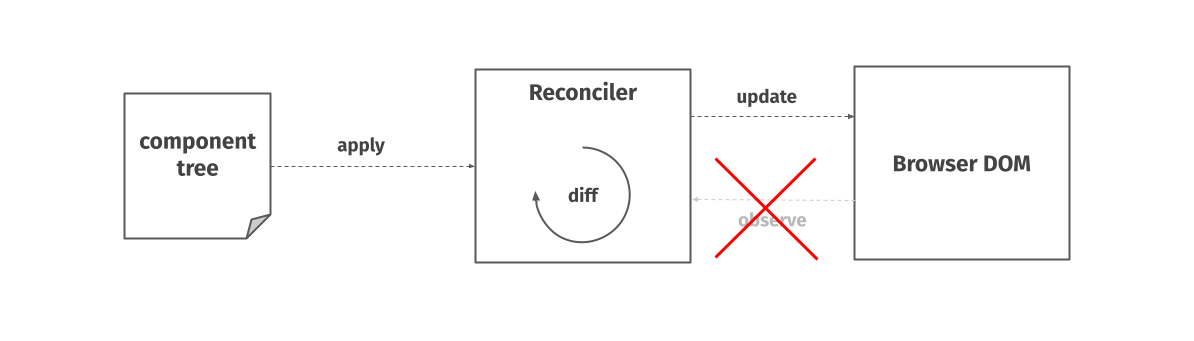
For one, that would probably be prohibitively slow. It also just doesn’t need to. Unlike many other desired-state systems, React operates with the assumption that it is the only thing touching its domain. It generally assumes that there is no other library or person modifying the page under its feet. You can test this yourself using developer tools in your browser. If you modify an HTML element controlled by React, the library will not try to overwrite your modification unless a parent of the changed element gets rerendered and the whole subtree replaced.
A nice thing about React is that it’s built in a modular fashion. The part which talks to the DOM is a separate module called ReactDOM and can be replaced with different rendering targets, which React calls hosts. A different host is used for example in the mobile application framework React Native. When writing React Native, you still specify the user interface of your app as a tree of components. However instead of talking to the DOM, React talks to the Native APIs of mobile operating systems. It’s also relatively easy to extend React with custom rendering targets yourself.
A more recent addition to React’s API are Hooks. They are an interesting design pattern that allows developers to manage state and side effects within components in a declarative way. I really recommend reading the blog post “Making setInterval declarative with React Hooks” by Dan Abramov where he wraps an inherently imperative API, namely the browser’s setInterval method, with a declarative hook.
Let’s go a bit further up the stack.
Terraform
Terraform is an open source infrastructure-as-code tool with the goal of providing one workflow to provision all infrastructure. It lets you specify parts of your infrastructure, most often the different types and instances of resources in your cloud provider, plus their configuration, as text files written in Terraform’s native language called HCL.
With these configuration files, you can perform what’s called a terraform plan, which lets you check whether the execution plan for a configuration matches your expectations before provisioning or changing your actual infrastructure.
When you first run Terraform, it creates a file called tfstate which stores the current state of your resources.
Every time you want to make changes to it, it will go and obtain the current state of your actual resources and report the changes your new plan will make. You can then check if your changes are correct and apply them.
Terraform as a desired state system
In the resulting diff you can then see what changes your new plan would make, but also whether your actual state has drifted from your saved tfstate. In other words, unlike React, Terraform is a closed loop system. Ultimately, this is because it’s optimizing for solving a different problem - while React needs to have fast updates and can assume that no one else touches its domain, Terraform can spend much more time (and does) figuring out the difference to the actual state. It crucially cannot assume resources it manages are left untouched.
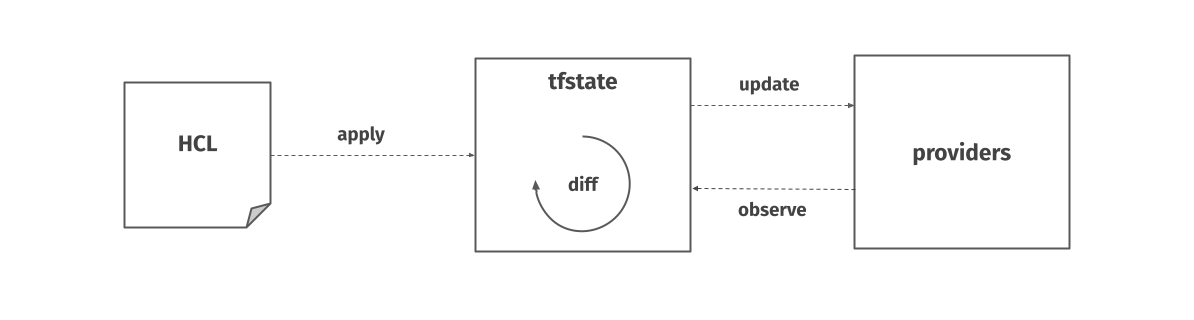
Much like you can extend React with different hosts, Terraform has a collection of plugins called providers that you can use. A provider is responsible for understanding the API interactions with some kind of service and exposing resources based on that API. And of course you can create your own. Unlike React, Terraform has an added complication of how to define what a resource is and what is its configuration. The configuration can be specified as its own resource or just be a part of the parent resource. This can vary between providers and many resource types support both. One of the harder parts of Terraform is managing this coupling.
Compared to some configuration management tools like Chef or SaltStack, Terraform works on the principle of immutable deployments. When you change your plan, your resources get recreated with the correct state applied. This means that operations can be inherently destructive. Making a configuration change on a VM could mean destroying the original VM and provisioning a new one. Which operations are destructive and which are not are defined by each provider. On the other hand, with mutable deployments you are much more likely to get into a situation where the actual state starts to drift from the desired state. In other words, changes to the Terraform state are idempotent – if you keep reapplying the same state which creates 10 VMs, you always just end up with 10 VMs. This is a crucial property of a desired state system.
Let’s now shift gears from provisioning to container orchestration.
Kubernetes
You’ve probably all heard of Kubernetes. It’s an open source system created by Google used for automating the deployment, scaling and management of containerized applications. In order to achieve its promise, it arguably takes the idea of a desired state system to its highest level.
Kubernetes manages containerized workflows inside a cluster of machines, which are called nodes. These can be physical or virtual machines. The smallest units of work are called pods and they can be scheduled to run on the nodes. Ultimately, a particular container with our code is going to be running inside this pod. Pods are organized in several kinds of resources, most often the kind called deployments. Their networking can be defined with a different type of resource, called a service. Many other kinds of resources exist, and custom ones can be created.
Kubernetes itself runs on the side of these nodes as a collection of services called the control plane. The control plane is responsible for serving the API, keeping track of resources and other tasks necessary to keep the system running.
The cluster can be controlled by a command line tool called kubectl which serves as the interface for Kubernetes.
While it also offers a sort-of imperative-like API, the core of its use is done using yaml configuration files which are then applied as a desired state to the cluster.
Kubernetes as a desired state system
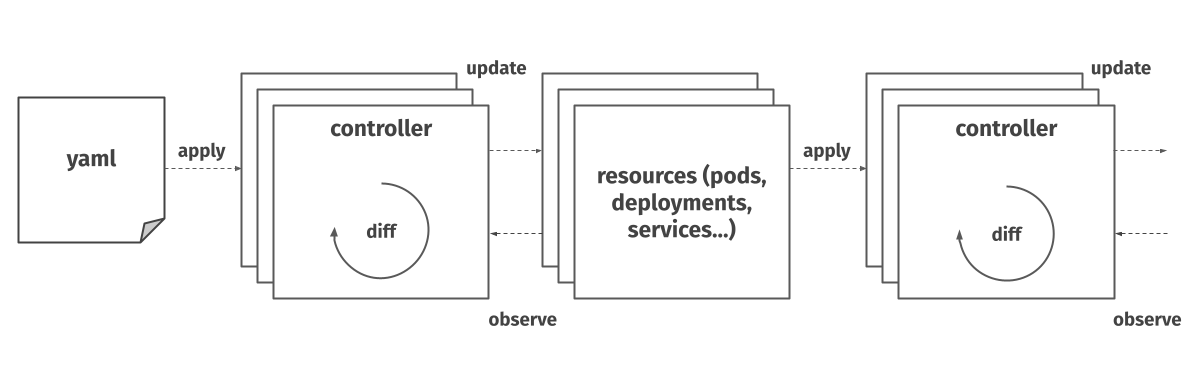
We can then look at Kubernetes through the lens of our model. Similarly to Terraform, you give the system the desired state of a particular resource in the cluster, this time in the form of a yaml file.
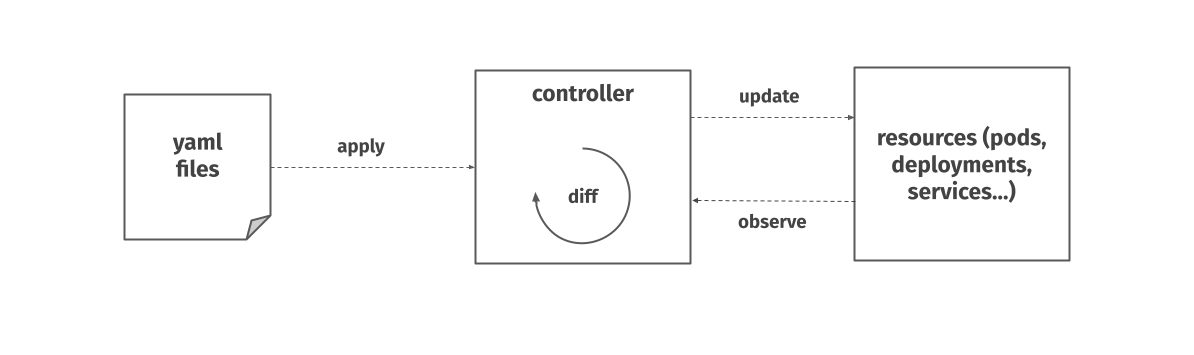
A component called a controller inside Kubernetes then has the responsibility to bring the actual state of the given resource in line with the desired state. Unlike Terraform, this happens continuously. If you try to delete one of the pod replicas in a deployment with 3 desired replicas, Kubernetes will immediately spin up a new one. Likewise, if a pod keeps crashing, it’s going to keep trying to run, as it tries to keep the actual state in line with the desired state. Kubernetes is a closed-loop system.
Another interesting concept from control theory which comes up in a system with continual desired state reconciliation is hysteresis.
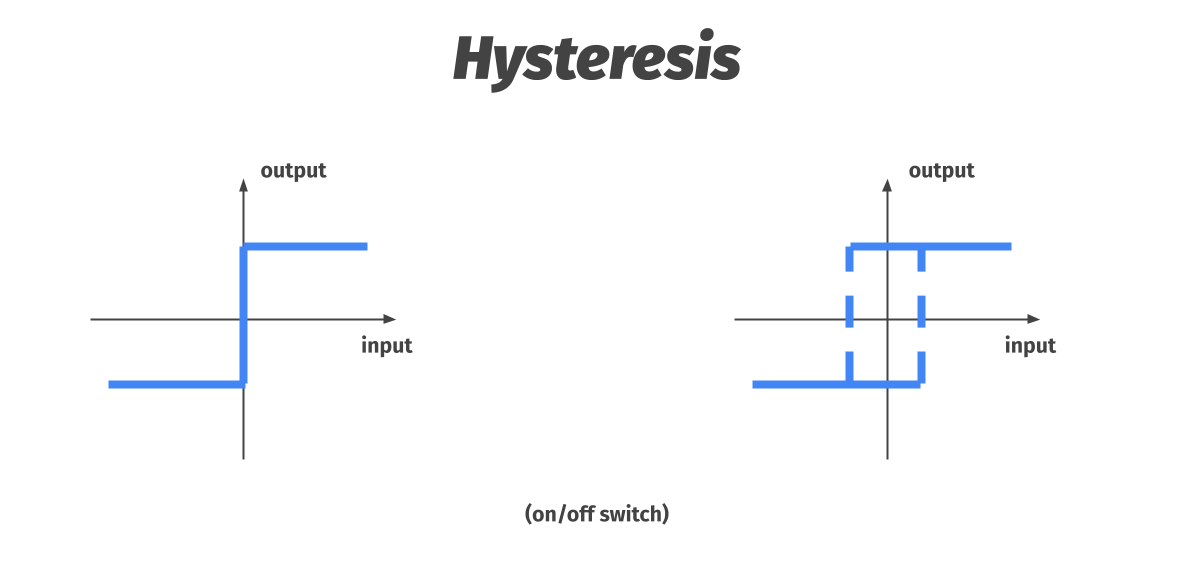
Control theory: Hysteresis
Hysteresis characterizes a system whose behaviour does not only depend on its input at time t, but also on the history of this input. You can also think of it as adding artificial lag to the system. A widely used example of this is a thermostat. Let’s say we set the thermostat to a temperature of 20 degrees. Without hysteresis, as soon as the temperature hits this desired state, the heating turns off. But that means that very quickly, the temperature goes back down under 20 degrees, turning the heating back on. The thermostat system starts oscillating and quickly turning the heating on and off. When we add hysteresis, the thermostat waits until the temperature is above, say 22 degrees before turning the heating off. Likewise, the thermostat will wait until the temperature hits less than, say 18 degrees before turning the heating back on. This ensures smoother and more reliable operation of the system. [3]
Kubernetes controllers
In Kubernetes, this concept comes into play when it has to decide whether to move some workloads off of a Node whose computational resources are dwindling, so called pod eviction. A soft grace period can be specified, which means the Kubernetes will wait for a while before scheduling the pod away from the Node, as the resource constraints might be a temporary situation. This ensures more predictable and smoother operation of the scheduling.
Kubernetes is actually made up of many of controllers, working together to bring the actual state close to the desired one. Each controller can act upon one or more resource types.
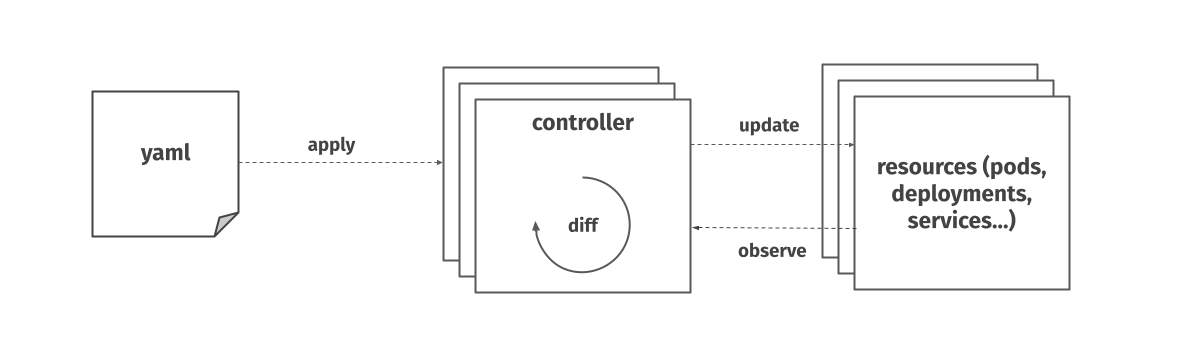
These controllers are actually often nested – a particular control loop (controller) uses one kind of resource as its desired state, and has a different kind of resource that it manages to make that desired state happen.
Allow me one more digression into basics of control theory, this one comes from circuit design and CPU interrupts.
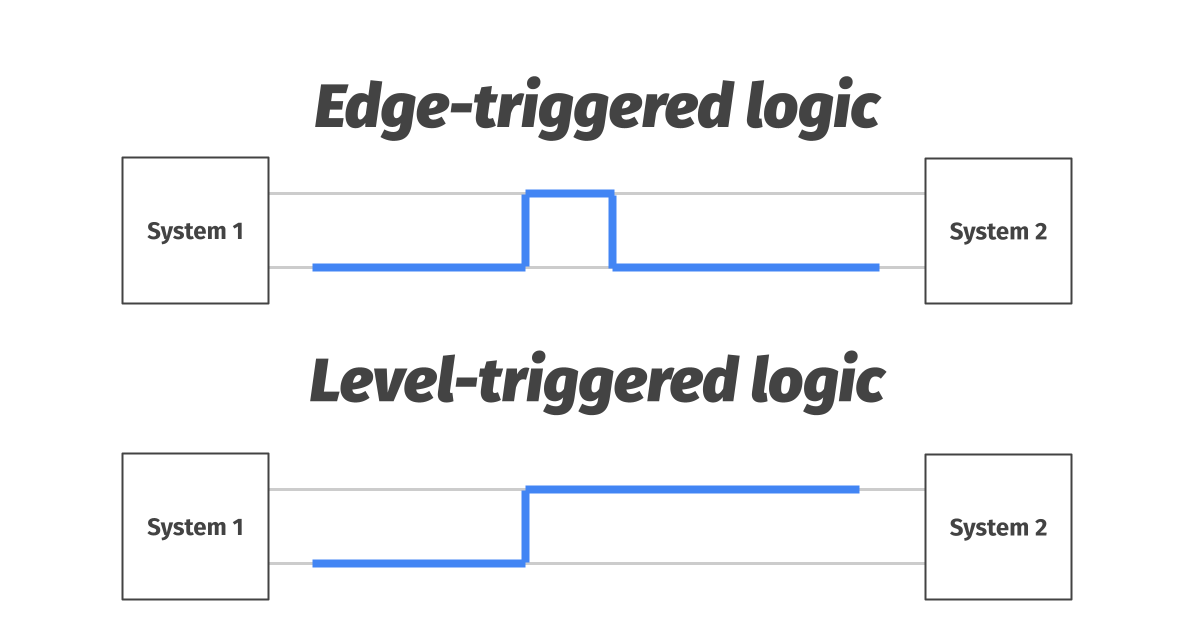
Control theory: Edge- vs level-triggered logic
When one system needs to give another some information over the wire, there are two options. The first one is called edge-triggered logic – system 1 pulses the line with a brief high voltage spike. The problem with this approach is that system 2 might miss the signal if it’s not listening at the time.
The second option is what we call level-triggered logic. In this case, system 1 brings the voltage up and keeps it there until it’s sure it’s been registered by system 2. This approach is more robust, as system 2 can check the state of the wire at any time. [4]
You can maybe see some parallels between this and event driven communication versus polling for changes.
But let’s get back to Kubernetes controllers. Where React needs to optimize for fast updates to the browser DOM, Kubernetes needs to optimize the observe part of the reconciliation loop. This is because at any point, a huge number of controllers might need to ask for the state of particular resources. To continuously poll for this information would be inefficient at scale. Therefore, most controllers use a hybrid approach between edge and level triggered logic, called a list-watch pattern.
In this pattern, the controllers first ask for the current state, then cache it, and keep a stream of events open for immediate updates to their cache. Unlike a pure event stream, this system is robust to crashes and networking issues as controllers can re-assert the state at any time.
Let’s look at one more way of how we can describe the desired-state model.
Value vs reference semantics
We can think of it as wrapping reference semantics with value semantics. When we treat objects as values, we assume they cannot be changed, that they are immutable (object in this case meaning generally a thing we work with, some piece of data). When programming, we don’t have to worry about the difference between the integer 5, and the integer 4 to which we added the integer 1 later. Five equals five either way. In other words, it is the content of the object which provide the object identity, and not our reference to it.
A desired state is just a collection of values which we want to exist in the world. Instead of keeping track of references to browser DOM nodes in React, or containers in Kubernetes, or Virtual Machines in Terraform, we can simply treat them as values. Values can’t be changed, if we need another one, we must create a new one. The underlying system takes care of all the mutable logic underneath. In some way, immutable strings in your favourite programming language can be just thought of as a desired state system, where the compiler or interpreter makes sure to reconcile the value semantics with the underlying memory references in a performant way. Doing this for complex objects is not easy at all, and often not possible.
However, I find it pretty fascinating trying to think of how could treat something like a networking socket, a database or other inherently stateful objects as a value.
Considerations
Let’s finish of with listing some of the considerations you have to keep in mind when designing a system like this.
1. Worth the complexity?
First of all, you have to ask yourself the question of whether it is necessary. Does it solve a real problem. Adding abstractions always leads to more complexity under the hood and it’s important to make the cost-benefit analysis of whether this extra complexity is worth it. A declarative API wrapping over an imperative API might seem a lot simpler for the people using it, but it’s internal complexity is always higher.
2. Constraining the API
Is it useful for us to constrain what the user of our interface can and cannot do in this way? Are we sure we want to give the user less control? Do we know exactly how we want to steer the API?
3. Closed or open loop
Do we need an open or closed loop system? In other words, are we the only person in the sandbox? Can we be sure that we are the only ones controlling the underlying API, and no one else is stepping on our toes?
4. Concurrency
Do we need to solve the situation that there can be concurrent updates happening to our interface, from multiple users? How about multiple updates from the same user? How can we reconcile multiple conflicting desired states?
5. Optimization
Can a stateless interface and constraining the surface of the API help us optimize the system in any way?
6. Time
How do we deal with the fact that things take time. While our API may treat some object or resource as a value, inside of our system, we might need to wait in order to create it, destroy it, update it. How is this communicated to the user, and does it need to be?
Having to think about time is the crucial difference between stateful and stateless systems. Time is one of the main sources of complexity when trying to map elegant mathematical models to the real world.
7. Diffing performance
What’s the structure of our states, and how quickly can we compare them. This might or might not be a bottleneck, depending on the structure and the nature of the underlying API.
8. Observe and update performance
How fast is the underlying API, whether that’s the observe or update part. Generally, a desired state system is going to be slower than just directly operating on the underlying API. You will always need to weigh the performance hit against the benefits of using such an abstraction.
9. Keeping track of resources
How can we keep track which of the resources in the underlying API we control. This is especially important in a distributed system like Kubernetes, where many control loops run at the same time.
10. Escape hatches
Do we need to add escape hatches to our interface so that the user can drop down to the imperative interface if needed? This might be for performance reasons or for allowing the user greater flexibility when it is really needed. React allows you to directly talk to the browser DOM if you need to. Even though it’s discouraged, occasionally it’s necessary to do so. Similarly, Kubernetes lets you drop down directly in the shell of an application running in a pod, if necessary.
Conclusion
I went through my view of what a desired-state system is and what are its central principles, I showed you some examples of where it’s used and presented what I find are the important considerations you should keep in mind when using this abstraction.
The ideas I presented here are nothing new, and most of you have probably thought about this in some capacity. I hope that by going through it in a bit more structured manner you now have a clearer picture, or mental model, in your head that helps you in your work.
At the of the day the world around us is not mathematical, but inherently mutable and stateful. We are limited by the fact that at the bottom of all our programs sits a von Neuman computer with a central processing unit, a data store and a connecting tube that can transmit a single word between the CPU and the store. An inherently mutable and imperative interface.
But thanks to abstractions, sometimes, and in limited scope, we can pretend that’s not the case and simplify our interfaces.
Sources:
- https://mitpress.mit.edu/books/concepts-techniques-and-models-computer-programming
- https://www.joelonsoftware.com/2002/11/11/the-law-of-leaky-abstractions
- https://fbswiki.org/wiki/index.php/Feedback_Systems:_An_Introduction_for_Scientists_and_Engineers
- https://speakerdeck.com/thockin/edge-vs-level-triggered-logic